

Re方向的题也是AK了喵(骄傲,队伍里面其他同学也是非常厉害,总之这次比赛还是收获蛮大的,以赛代学真的能学到不少东西
接下来就是本次题目的一些wp及其讲解,有的过于简单的我就不详细说了
ezzz_math
这道题属于是签到题,程序拖到ida中发现有一个方程组,将其解开之后即可获得flag
ezpy和ELF
这两道题都是简单的python逆向题目,python逆向题跟我之前的文章方法都差不多,一般套路是python反编译+加密算法,这种也都是板子题非常简单
其中ezpy反编译后是RC4加密(这个就不说了),而ELF关键逻辑还原成可读代码如下:
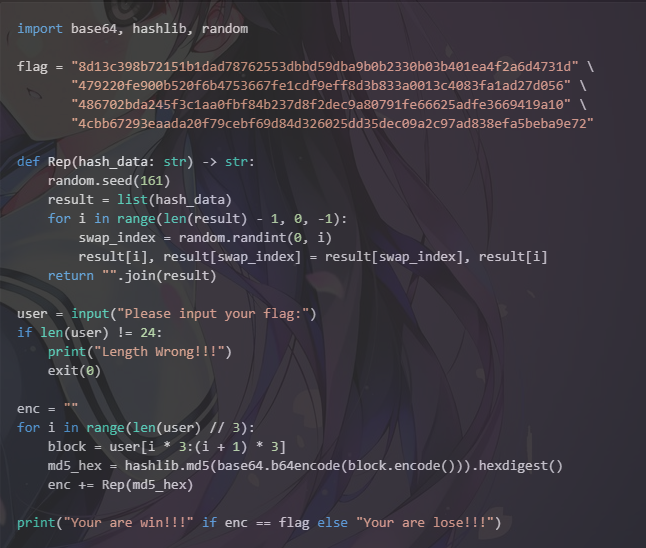
逆向思路
- 输入长度固定 24,被分成 8 个 3 字节块;每块会
base64后取md5.hexdigest()(32 字符)。 Rep只是用固定种子161对 32 字符串做 Fisher–Yates 洗牌,所以每次的置换是恒定的,可提前算出逆置换。- 给定的
flag长度 256 = 8×32,可按 32 分块,每块逆洗牌即可还原原始 md5 值。 - 每个原始块只有 3 字节,可在可打印 ASCII 范围内暴力枚举
product(charset, repeat=3),找到满足md5(base64(block)) == target_md5的明文。
MysteriousStream
一开始发现文件有两个,一个是challenge还有一个是payload.dat
那么我们先用exeinfo查看一下文件类型
发现没有加壳,那么我们直接拖到ida中进行分析
找到了main函数,并对其进行反编译
int __fastcall main(int argc, const char **argv, const char **envp)
{
FILE *v3; // rax
FILE *v4; // r12
__int64 v5; // r14
char *v6; // rax
char *v7; // rbp
size_t v8; // r13
__int64 i; // rcx
char v11[17]; // [rsp+7h] [rbp-41h] BYREF
unsigned __int64 v12; // [rsp+18h] [rbp-30h]
v12 = __readfsqword(0x28u);
v3 = fopen("payload.dat", "rb");
if ( v3 )
{
v4 = v3;
fseek(v3, 0LL, 2);
v5 = ftell(v4);
if ( v5 < 0 )
{
puts("Get file size failed");
fclose(v4);
return 1;
}
else
{
fseek(v4, 0LL, 0);
v6 = (char *)malloc(v5);
v7 = v6;
if ( v6 )
{
v8 = fread(v6, 1uLL, v5, v4);
fclose(v4);
if ( v5 == v8 )
{
qmemcpy(v11, "P4ssXORSecr3tK3y!", sizeof(v11));
rc4_variant(v7, v8, &v11[7], 10LL);
if ( v8 )
{
for ( i = 0LL; i != v8; ++i )
v7[i] ^= v11[i % 7];
}
__printf_chk(1LL, "Result: %s\n", v7);
free(v7);
return 0;
}
else
{
__printf_chk(1LL, "Read failed! Expected %ld bytes, got %zu bytes\n", v5, v8);
free(v7);
return 1;
}
}
else
{
puts("Malloc memory failed");
fclose(v4);
return 1;
}
}
}
else
{
puts("payload.dat not found");
return 1;
}
}
这段 main 的核心作用就是从 payload.dat 读入一段数据,然后用“两层解密/反混淆”还原成字符串并打印。
也就是payload.dat 的内容 → 先做 RC4 变种处理(key="Secr3tK3y!")→ 再做重复 XOR(key="P4ssXOR")→ 得到字符串输出。
payload.dat用ida打开发现只有下面 40 字节,因此这就是密文

所以写一个python解密脚本就可以了
enc_hex = "f1c652acab33ee6873cea53f0e0eb7fdc731be9aa7e8d41fe04b3154ff7cccd2160b4034e6b815bf"
enc = bytes.fromhex(enc_hex)
xor_key = b"P4ssXOR"
rc4_key = b"Secr3tK3y!"
#### XOR
tmp = bytes(b ^ xor_key[i % len(xor_key)] for i, b in enumerate(enc))
#### RC4 变体
S = list(range(256)); j = 0
for i in range(256):
j = (j + S[i] + rc4_key[i % len(rc4_key)] + (i & 0xAA)) & 0xFF
S[i], S[j] = S[j], S[i]
i = j = 0
out = bytearray(tmp)
for k in range(len(out)):
i = (i + 1) & 0xFF
j = (j + S[i]) & 0xFF
S[i], S[j] = S[j], S[i]
out[k] ^= S[(S[i] + S[j]) & 0xFF]
print(out.decode())最终输出flag为ISCTF{Y0u_a2e_2ea11y_a_1aby2inth_master}
小蓝鲨的单片机_1
以前没接触过硬件反编译,这次出了两道硬件逆向的题,只好硬着头皮做了
首先打开压缩包发现这些东东(我不认识啊)
之后直接使用8051反汇编器进行反汇编
--- Pass 1: Analyzing code flow... ---
--- Pass 2: Generating disassembly (31 code bytes, 4 labels identified) ---
0000: 21 00 AJMP L_0100
L_0100:
0100: 75 80 FF MOV P0, #0FFH
0103: 75 A0 FF MOV P2, #0FFH
0106: 90 02 07 MOV DPTR, #00207H
L_0109:
0109: E5 A0 MOV A, P2
010B: F4 CPL A
010C: F5 A0 MOV P2, A
010E: 74 00 MOV A, #000H
0110: 31 1C ACALL L_011C
0112: A3 INC DPTR
0113: 93 MOVC A, @A+DPTR
0114: F4 CPL A
0115: F5 80 MOV P0, A
0117: B4 00 EF CJNE A, #000H, L_0109
011A: 80 E4 SJMP L_0100
L_011C:
011C: 00 NOP
011D: 00 NOP
011E: 00 NOP
011F: C0 30 PUSH 30H
0121: C0 31 PUSH 31H
0123: C0 32 PUSH 32H
0125: 75 30 22 MOV 30H, #022H
0128: 75 31 9F MOV 31H, #09FH
012B: 75 32 38 MOV 32H, #038H
L_012E:
012E: D5 32 FD DJNZ 32H, L_012E
0131: D5 31 FA DJNZ 31H, L_012E
0134: D5 30 F7 DJNZ 30H, L_012E
0137: D0 32 POP 32H
0139: D0 31 POP 31H
013B: D0 30 POP 30H
013D: 22 RET
0208: DB 03CH, 018H, 018H, 018H, 018H, 018H, 03CH, 000H
0210: DB 03CH, 042H, 040H, 03CH, 002H, 042H, 03CH, 000H
0218: DB 03CH, 042H, 040H, 040H, 040H, 042H, 03CH, 000H
0220: DB 07EH, 008H, 008H, 008H, 008H, 008H, 008H, 000H
0228: DB 07EH, 040H, 040H, 07CH, 040H, 040H, 040H, 000H
0230: DB 01EH, 010H, 010H, 020H, 010H, 010H, 01EH, 000H
0238: DB 042H, 042H, 042H, 05AH, 07EH, 066H, 042H, 000H
0240: DB 000H, 000H, 03CH, 042H, 042H, 042H, 03CH, 000H
0248: DB 000H, 000H, 042H, 042H, 05AH, 07EH, 042H, 000H
0250: DB 000H, 000H, 000H, 000H, 000H, 000H, 07EH, 000H
0258: DB 042H, 042H, 042H, 03CH, 018H, 018H, 018H, 000H
0260: DB 000H, 000H, 03CH, 042H, 042H, 042H, 03CH, 000H
0268: DB 000H, 000H, 042H, 042H, 042H, 042H, 03EH, 000H
0270: DB 000H, 000H, 000H, 000H, 000H, 000H, 07EH, 000H
0278: DB 018H, 024H, 042H, 042H, 07EH, 042H, 042H, 000H
0280: DB 000H, 000H, 05CH, 062H, 040H, 040H, 040H, 000H
0288: DB 000H, 000H, 03CH, 042H, 07EH, 040H, 03CH, 000H
0290: DB 000H, 000H, 000H, 000H, 000H, 000H, 07EH, 000H
0298: DB 03CH, 042H, 040H, 04EH, 042H, 042H, 03EH, 000H
02A0: DB 000H, 000H, 03CH, 042H, 042H, 042H, 03CH, 000H
02A8: DB 000H, 000H, 03CH, 042H, 042H, 042H, 03CH, 000H
02B0: DB 002H, 002H, 032H, 04AH, 04AH, 04AH, 03EH, 000H
02B8: DB 000H, 000H, 000H, 000H, 000H, 000H, 07EH, 000H
02C0: DB 018H, 024H, 042H, 042H, 07EH, 042H, 042H, 000H
02C8: DB 010H, 010H, 07EH, 010H, 010H, 010H, 00EH, 000H
02D0: DB 000H, 000H, 000H, 000H, 000H, 000H, 07EH, 000H
02D8: DB 03EH, 020H, 020H, 03CH, 002H, 002H, 03CH, 000H
02E0: DB 010H, 030H, 010H, 010H, 010H, 010H, 038H, 000H
02E8: DB 078H, 008H, 008H, 00CH, 008H, 008H, 078H, 000H
02F0: DB 0FFH
--- 反汇编完成 ---扔给ai翻译之后发现数据区很像 8×8 点阵字模,尤其前面几组非常像常见 8×8 大写字母:
0208 这一组看起来像 I
0210 很像 S
0218 很像 C
0220 很像 T
0228 很像 F
所以把剩下的全部弄出来就好了
以下是代码
from PIL import Image, ImageDraw
# 末尾 0xFF 是结束符,不属于 8x8 字符本体
ROM_BYTES = [
0x3C, 0x18, 0x18, 0x18, 0x18, 0x18, 0x3C, 0x00, # 0208
0x3C, 0x42, 0x40, 0x3C, 0x02, 0x42, 0x3C, 0x00, # 0210
0x3C, 0x42, 0x40, 0x40, 0x40, 0x42, 0x3C, 0x00, # 0218
0x7E, 0x08, 0x08, 0x08, 0x08, 0x08, 0x08, 0x00, # 0220
0x7E, 0x40, 0x40, 0x7C, 0x40, 0x40, 0x40, 0x00, # 0228
0x1E, 0x10, 0x10, 0x20, 0x10, 0x10, 0x1E, 0x00, # 0230
0x42, 0x42, 0x42, 0x5A, 0x7E, 0x66, 0x42, 0x00, # 0238
0x00, 0x00, 0x3C, 0x42, 0x42, 0x42, 0x3C, 0x00, # 0240
0x00, 0x00, 0x42, 0x42, 0x5A, 0x7E, 0x42, 0x00, # 0248
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x7E, 0x00, # 0250
0x42, 0x42, 0x42, 0x3C, 0x18, 0x18, 0x18, 0x00, # 0258
0x00, 0x00, 0x3C, 0x42, 0x42, 0x42, 0x3C, 0x00, # 0260
0x00, 0x00, 0x42, 0x42, 0x42, 0x42, 0x3E, 0x00, # 0268
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x7E, 0x00, # 0270
0x18, 0x24, 0x42, 0x42, 0x7E, 0x42, 0x42, 0x00, # 0278
0x00, 0x00, 0x5C, 0x62, 0x40, 0x40, 0x40, 0x00, # 0280
0x00, 0x00, 0x3C, 0x42, 0x7E, 0x40, 0x3C, 0x00, # 0288
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x7E, 0x00, # 0290
0x3C, 0x42, 0x40, 0x4E, 0x42, 0x42, 0x3E, 0x00, # 0298
0x00, 0x00, 0x3C, 0x42, 0x42, 0x42, 0x3C, 0x00, # 02A0
0x00, 0x00, 0x3C, 0x42, 0x42, 0x42, 0x3C, 0x00, # 02A8
0x02, 0x02, 0x32, 0x4A, 0x4A, 0x4A, 0x3E, 0x00, # 02B0
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x7E, 0x00, # 02B8
0x18, 0x24, 0x42, 0x42, 0x7E, 0x42, 0x42, 0x00, # 02C0
0x10, 0x10, 0x7E, 0x10, 0x10, 0x10, 0x0E, 0x00, # 02C8
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x7E, 0x00, # 02D0
0x3E, 0x20, 0x20, 0x3C, 0x02, 0x02, 0x3C, 0x00, # 02D8
0x10, 0x30, 0x10, 0x10, 0x10, 0x10, 0x38, 0x00, # 02E0
0x78, 0x08, 0x08, 0x0C, 0x08, 0x08, 0x78, 0x00, # 02E8
0xFF, # 02F0 terminator
]
def chunk_glyphs(data):
# 移除末尾 terminator 0xFF(只移除尾部连续的 FF)
while data and data[-1] == 0xFF:
data = data[:-1]
# 8 字节一组
if len(data) % 8 != 0:
raise ValueError(f"Byte length not multiple of 8: {len(data)}")
return [data[i:i+8] for i in range(0, len(data), 8)]
def glyph_to_matrix(glyph, msb_left=True):
# 每个字节一行
m = []
for b in glyph:
row = []
for x in range(8):
bit = (b >> (7 - x)) & 1 if msb_left else (b >> x) & 1
row.append(bit)
m.append(row)
return m
def transpose8(m):
return [[m[y][x] for y in range(8)] for x in range(8)]
def render_strip(glyphs, scale=16, gap=1, msb_left=True,
invert=False, by_column=False):
"""
scale: 每个点放大倍数
gap: 字符间间隔(以“原始像素”为单位,会随 scale 放大)
msb_left: True=bit7在左
invert: True=黑白反转
by_column: True=把字模按“列存储”理解(相当于转置)
"""
mats = []
for g in glyphs:
m = glyph_to_matrix(g, msb_left=msb_left)
if by_column:
m = transpose8(m)
if invert:
m = [[1 - v for v in row] for row in m]
mats.append(m)
n = len(mats)
width = n * 8 * scale + (n - 1) * gap * scale
height = 8 * scale
img = Image.new("1", (width, height), 1) # 1=白底
draw = ImageDraw.Draw(img)
x_offset = 0
for m in mats:
for y in range(8):
for x in range(8):
if m[y][x]:
x0 = x_offset + x * scale
y0 = y * scale
draw.rectangle([x0, y0, x0 + scale - 1, y0 + scale - 1], fill=0)
x_offset += 8 * scale + gap * scale
return img
if __name__ == "__main__":
glyphs = chunk_glyphs(ROM_BYTES)
最后是这个

小蓝鲨的单片机_2
附件还是一堆乱七八糟的和一个note.txt
其中note.txt的内容是
;EN = P2.7
;RS = P2.6 ;PUZHONG-A2
;RW = P2.5
;EN = P2.1
;RS = P2.4 ;IKMSIK V2.1
;RW = P2.3
;DATA = P0
;we use R0 register as the param register.
;we use R1 register as the Line-Column register.
;we use R3,R4 registers as the str_addr register, R3 = High_addr, R4 = Low_addr.
;Databuffer is P0 SFR Register.
;R7 register is the counter扔给ai后发现是一段给 8051 + 1602/HD44780 LCD 驱动程序用的“硬件连线说明 + 寄存器约定”注释
作用就是:
告诉你 LCD 怎么接线
告诉你这些汇编函数怎么“传参”
但其实你把汇编码直接扔给ai也是一样的
因此通过51反汇编之后发现汇编码主要做了这些工作
配置端口
通过 P0(数据) + P2(控制) 初始化并驱动 1602/HD44780 LCD
使用忙标志轮询 + 软件延时保证时序
从程序存储器中取两行“被 XOR 0xA2 混淆过的字符串”
解码后显示在 LCD 的第一、第二行
最终进入死循环保持显示
下面是关键数据
01CC: EB F1 E1 F6 E4 D9 F5 CD D5 FD FB CD D7 FD E3 D0
01DC: C7 FD 97 93 FD EF C3 D1 D6 C7 D0 DF 82 82 82 82按程序逻辑每个字节 XOR 0xA2 后就是要显示的 ASCII
最终解出ISCTF{Wow_You_Are_51_Master}VM_COOL
重量级来了,vm壳真是一个硬骨头
之前N1CTF的时候就遇到VM壳了,当时真是一点不会,现在特意弄了一下vm壳是怎么个原理
简单来说就是程序运行时通过解释操作码(opcode)选择对应的函数(handle)执行
那么啥也不说了直接拖到ida里面看一下主函数吧
int __fastcall main(int argc, const char **argv, const char **envp)
{
__int64 v4[4]; // [rsp+0h] [rbp-220h] BYREF
__int64 v5; // [rsp+20h] [rbp-200h]
__int64 v6; // [rsp+28h] [rbp-1F8h]
__int64 v7; // [rsp+30h] [rbp-1F0h]
_BYTE v8[15]; // [rsp+38h] [rbp-1E8h]
char v9; // [rsp+47h] [rbp-1D9h]
__int64 v10; // [rsp+48h] [rbp-1D8h]
__int64 v11; // [rsp+50h] [rbp-1D0h]
__int64 v12; // [rsp+58h] [rbp-1C8h]
__int64 v13; // [rsp+60h] [rbp-1C0h]
__int64 v14; // [rsp+68h] [rbp-1B8h]
__int64 v15; // [rsp+70h] [rbp-1B0h]
__int64 v16; // [rsp+78h] [rbp-1A8h]
__int64 v17; // [rsp+80h] [rbp-1A0h]
__int64 v18; // [rsp+88h] [rbp-198h]
__int64 v19; // [rsp+90h] [rbp-190h]
__int64 v20; // [rsp+98h] [rbp-188h]
__int64 v21; // [rsp+A0h] [rbp-180h]
__int64 v22; // [rsp+A8h] [rbp-178h]
__int64 v23; // [rsp+B0h] [rbp-170h]
__int64 v24; // [rsp+B8h] [rbp-168h]
__int64 v25; // [rsp+C0h] [rbp-160h]
__int64 v26; // [rsp+C8h] [rbp-158h]
__int64 v27; // [rsp+D0h] [rbp-150h]
__int64 v28; // [rsp+D8h] [rbp-148h]
__int64 v29; // [rsp+E0h] [rbp-140h]
__int64 v30; // [rsp+E8h] [rbp-138h]
__int64 v31; // [rsp+F0h] [rbp-130h]
__int64 v32; // [rsp+F8h] [rbp-128h]
char v33[284]; // [rsp+100h] [rbp-120h] BYREF
unsigned int i; // [rsp+21Ch] [rbp-4h]
v9 = 0;
v10 = 0LL;
v11 = 0LL;
v12 = 0LL;
v13 = 0LL;
v14 = 0LL;
v15 = 0LL;
v16 = 0LL;
v17 = 0LL;
v18 = 0LL;
v19 = 0LL;
v20 = 0LL;
v21 = 0LL;
v22 = 0LL;
v23 = 0LL;
v24 = 0LL;
v25 = 0LL;
v26 = 0LL;
v27 = 0LL;
v28 = 0LL;
v29 = 0LL;
v30 = 0LL;
v31 = 0LL;
v32 = 0LL;
v4[0] = vm_program;
v4[1] = qword_4068;
v4[2] = qword_4070;
v4[3] = qword_4078;
v5 = qword_4080;
v6 = qword_4088;
LOWORD(v5) = -21737;
BYTE2(v5) = 55;
BYTE5(v4[0]) = 1;
v7 = encrypted_flag;
*(_QWORD *)v8 = qword_4048;
*(_QWORD *)&v8[7] = *(__int64 *)((char *)&qword_4048 + 7);
init_vm(v33, v4, 256LL);
run_vm(v33);
printf("Decrypted flag: ");
for ( i = 0; i <= 0x16; ++i )
putchar((unsigned __int8)v33[i + 64]);
putchar(10);
return 0;
}这段 main 的工作流程是:
- 准备 VM 所需的指令流/常量段/配置段
- 运行前对其中几个值做字节级修补
- 拷贝一段15 字节关键常量
init_vm建立 VM 上下文run_vm执行 VM 解密逻辑- 从
v33+64开始取出 23 字节当作 flag 打印
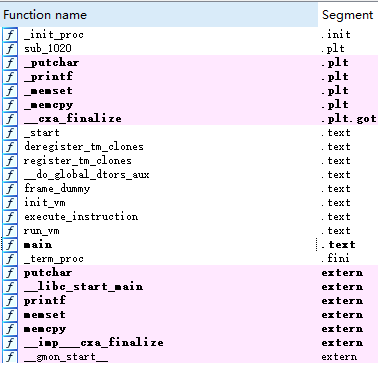
由上图可知程序内的函数,那么让我们解释其作用
init_vm
_DWORD *__fastcall init_vm(_DWORD *a1, const void *a2, int a3)
{
_DWORD *result; // rax
memset(a1, 0, 0x110uLL);
memcpy(a1, a2, a3);
result = a1;
a1[67] = 1;
return result;
}这是VM 上下文初始化函数,把 VM 运行所需的初始数据块(从栈上拼好的那一坨)拷贝进 VM 上下文,并打一个“已就绪”标记。
接下来看run_vm
__int64 __fastcall run_vm(__int64 a1)
{
__int64 result; // rax
while ( 1 )
{
result = *(unsigned int *)(a1 + 268);
if ( !(_DWORD)result )
break;
result = *(unsigned __int16 *)(a1 + 264);
if ( (unsigned __int16)result > 0xFFu )
break;
execute_instruction(a1);
}
return result;
}run_vm 就是:当“运行标志=1”且“指令指针 IP 在 0..255 范围内”时,循环取指并执行
发现有一个execute_instruction函数,我们也看一下
__int64 __fastcall execute_instruction(__int64 a1)
{
unsigned __int16 v1; // ax
unsigned __int16 v2; // ax
unsigned __int16 v3; // ax
char v4; // cl
__int64 result; // rax
unsigned __int16 v6; // ax
unsigned __int16 v7; // ax
char v8; // cl
unsigned __int16 v9; // ax
unsigned __int16 v10; // ax
unsigned __int16 v11; // ax
char v12; // cl
unsigned __int16 v13; // ax
unsigned __int16 v14; // ax
unsigned __int16 v15; // ax
char v16; // cl
unsigned __int16 v17; // ax
unsigned __int16 v18; // ax
unsigned __int16 v19; // ax
unsigned __int16 v20; // ax
unsigned __int16 v21; // ax
int v22; // esi
unsigned __int16 v23; // ax
unsigned __int16 v24; // ax
int v25; // esi
unsigned __int16 v26; // ax
__int16 v27; // dx
unsigned __int16 v28; // ax
unsigned __int16 v29; // ax
unsigned __int16 v30; // ax
unsigned __int16 v31; // ax
bool v32; // dl
unsigned __int8 v33; // [rsp+1Ch] [rbp-4h]
unsigned __int8 v34; // [rsp+1Dh] [rbp-3h]
unsigned __int8 v35; // [rsp+1Dh] [rbp-3h]
unsigned __int8 v36; // [rsp+1Dh] [rbp-3h]
unsigned __int8 v37; // [rsp+1Eh] [rbp-2h]
unsigned __int8 v38; // [rsp+1Eh] [rbp-2h]
unsigned __int8 v39; // [rsp+1Eh] [rbp-2h]
unsigned __int8 v40; // [rsp+1Eh] [rbp-2h]
unsigned __int8 v41; // [rsp+1Eh] [rbp-2h]
unsigned __int8 v42; // [rsp+1Eh] [rbp-2h]
unsigned __int8 v43; // [rsp+1Eh] [rbp-2h]
unsigned __int8 v44; // [rsp+1Eh] [rbp-2h]
unsigned __int8 v45; // [rsp+1Eh] [rbp-2h]
unsigned __int8 v46; // [rsp+1Fh] [rbp-1h]
v1 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v1 + 1;
v46 = *(_BYTE *)(a1 + v1);
if ( v46 > 0xAu )
{
if ( v46 == 255 )
{
result = a1;
*(_DWORD *)(a1 + 268) = 0;
return result;
}
goto LABEL_18;
}
if ( !v46 )
{
LABEL_18:
printf("Unknown opcode: 0x%02X\n", v46);
result = a1;
*(_DWORD *)(a1 + 268) = 0;
return result;
}
switch ( v46 )
{
case 1u:
v2 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v2 + 1;
v37 = *(_BYTE *)(a1 + v2);
v3 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v3 + 1;
v4 = *(_BYTE *)(a1 + *(unsigned __int8 *)(a1 + v3));
result = v37;
*(_BYTE *)(a1 + v37 + 256) = v4;
break;
case 2u:
v6 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v6 + 1;
v38 = *(_BYTE *)(a1 + v6);
v7 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v7 + 1;
v8 = *(_BYTE *)(a1 + *(unsigned __int8 *)(a1 + v7) + 256);
result = v38;
*(_BYTE *)(a1 + v38) = v8;
break;
case 3u:
v9 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v9 + 1;
v39 = *(_BYTE *)(a1 + v9);
v10 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v10 + 1;
v34 = *(_BYTE *)(a1 + v10);
v11 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v11 + 1;
v12 = *(_BYTE *)(a1 + *(unsigned __int8 *)(a1 + v11) + 256) + *(_BYTE *)(a1 + v34 + 256);
result = v39;
*(_BYTE *)(a1 + v39 + 256) = v12;
break;
case 4u:
v13 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v13 + 1;
v40 = *(_BYTE *)(a1 + v13);
v14 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v14 + 1;
v35 = *(_BYTE *)(a1 + v14);
v15 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v15 + 1;
v16 = *(_BYTE *)(a1 + v35 + 256) - *(_BYTE *)(a1 + *(unsigned __int8 *)(a1 + v15) + 256);
result = v40;
*(_BYTE *)(a1 + v40 + 256) = v16;
break;
case 5u:
v17 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v17 + 1;
v41 = *(_BYTE *)(a1 + v17);
v18 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v18 + 1;
v36 = *(_BYTE *)(a1 + v18);
v19 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v19 + 1;
v33 = *(_BYTE *)(a1 + v19);
result = v41;
*(_BYTE *)(a1 + v41 + 256) = *(_BYTE *)(a1 + v33 + 256) ^ *(_BYTE *)(a1 + v36 + 256);
break;
case 6u:
v20 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v20 + 1;
v42 = *(_BYTE *)(a1 + v20);
v21 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v21 + 1;
v22 = *(unsigned __int8 *)(a1 + v42 + 256) << *(_BYTE *)(a1 + *(unsigned __int8 *)(a1 + v21) + 256);
result = v42;
*(_BYTE *)(a1 + v42 + 256) = v22;
break;
case 7u:
v23 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v23 + 1;
v43 = *(_BYTE *)(a1 + v23);
v24 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v24 + 1;
v25 = (int)*(unsigned __int8 *)(a1 + v43 + 256) >> *(_BYTE *)(a1 + *(unsigned __int8 *)(a1 + v24) + 256);
result = v43;
*(_BYTE *)(a1 + v43 + 256) = v25;
break;
case 8u:
v26 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v26 + 1;
v27 = *(unsigned __int8 *)(a1 + v26);
result = a1;
*(_WORD *)(a1 + 264) = v27;
break;
case 9u:
v28 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v28 + 1;
v44 = *(_BYTE *)(a1 + v28);
v29 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v29 + 1;
result = *(unsigned __int8 *)(a1 + *(unsigned __int8 *)(a1 + v29) + 256);
if ( !(_BYTE)result )
{
result = a1;
*(_WORD *)(a1 + 264) = v44;
}
break;
case 0xAu:
v30 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v30 + 1;
v45 = *(_BYTE *)(a1 + v30);
v31 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v31 + 1;
v32 = *(_BYTE *)(a1 + v45 + 256) == *(_BYTE *)(a1 + *(unsigned __int8 *)(a1 + v31) + 256);
result = a1;
*(_BYTE *)(a1 + 266) = v32;
break;
default:
goto LABEL_18;
}
return result;
}发现这是一个VM 指令解释器,execute_instruction 包含 opcode 的读取/解码逻辑 + dispatch + handlers
之后就是疯狂看代码,对该程序进行分析,导致我这道题做了两天
VM内存布局
偏移 0-255 (0x000-0x0FF): 代码/数据区域 (256字节)
偏移 256-263 (0x100-0x107): 寄存器区域 (8个字节寄存器 R0-R7)
偏移 264-265 (0x108-0x109): PC程序计数器 (16位)
偏移 266 (0x10A): 标志寄存器 (8位)
偏移 267 (0x10B): (未使用/填充)
偏移 268-271 (0x10C-0x10F): 运行状态标志 (32位, 1=运行中, 0=停止)┌─────────────────────────────────────────────┐
│ 偏移 0x000-0x0FF (256字节) │
│ 代码/数据混合区域 │
│ - 字节码程序 │
│ - 加密的flag数据 │
│ - 临时存储 │
├─────────────────────────────────────────────┤
│ 偏移 0x100-0x107 (8字节) │
│ 寄存器区域 (R0-R7) │
│ - 8个8位通用寄存器 │
├─────────────────────────────────────────────┤
│ 偏移 0x108-0x109 (2字节) │
│ PC 程序计数器 (16位) │
├─────────────────────────────────────────────┤
│ 偏移 0x10A (1字节) │
│ FLAG 标志寄存器 │
├─────────────────────────────────────────────┤
│ 偏移 0x10C-0x10F (4字节) │
│ 运行状态标志 (1=运行, 0=停止) │
└─────────────────────────────────────────────┘初始化流程
- init_vm: 清零内存,复制字节码,设置运行标志为1
- run_vm: 循环执行指令直到运行标志为0或PC超过255
- execute_instruction: 解码并执行单条指令
| Opcode | 助记符 | 参数 | 功能 | IDA地址 |
|---|---|---|---|---|
| 0x01 | LOAD | reg, [addr] | 从内存加载到寄存器 | 0x1241 |
| 0x02 | STORE | [addr], reg | 从寄存器存储到内存 | 0x12B8 |
| 0x03 | ADD | rd, rs1, rs2 | 寄存器加法 | 0x132F |
| 0x04 | SUB | rd, rs1, rs2 | 寄存器减法 | 0x13E6 |
| 0x05 | XOR | rd, rs1, rs2 | 寄存器异或 | 0x149D |
| 0x06 | SHL | rd, rs | 左移 | 0x1554 |
| 0x07 | SHR | rd, rs | 右移 | 0x15EE |
| 0x08 | JMP | addr | 无条件跳转 | 0x1688 |
| 0x09 | JZ | addr, reg | 零跳转 | 0x16C5 |
| 0x0A | CMP | r1, r2 | 比较 | 0x1745 |
| 0xFF | HALT | - | 停机 | 0x17CA |
| 其他 | ERROR | - | 错误 | 0x17DD |
到现在,我们应该已经把该VM的逻辑摸的差不多了,但是其中有许多坑点
混淆与陷阱
- 偏移 0x06 的 opcode=0x10 未定义,执行两条 LOAD 后触发 “Unknown opcode”,VM 立即停机。
- main将字节码 0x20-0x22 改写为 `17 AB 37`(同时把字节 0x05 置 0x01),破坏了原本的 STORE+ADD+CMP+JZ+JMP 解密循环。
所以说这是永远无法到达的解密的彼岸

那么我们应该怎么做呢?
无需跑原 VM,只要复原循环或直接重写算法即可
对的,我们只需要使用opcode那套鸟语来把算法翻译出来并解密就好了
最终还原出来
解密算法(VM 循环核心 基于XOR和加法的混合变换)
- 真实变换(加密方向):
r4 = (((x ^ key1) + key2) ^ key1) - key2 main写入的密钥:key1 = 0xAB,key2 = 0x37;字节 0x20 的 0x17 表示长度。
逆变换(解密)
t3 = (c + 0x37) & 0xFF
t2 = t3 ^ 0xAB
t1 = (t2 - 0x37) & 0xFF
p = t1 ^ 0xAB对 encrypted_flag 的每个字节执行上述逆变换即可。
- 解出的明文:
flag{VM_1s_reALly_c0oL}
ez_xtea
写太累了歇一会
Comments NOTHING