

首先exeinfo发现该程序是Linux 下的 64 位 ELF 动态库/可执行文件没检测出壳,之后将程序拖到ida里进行分析。
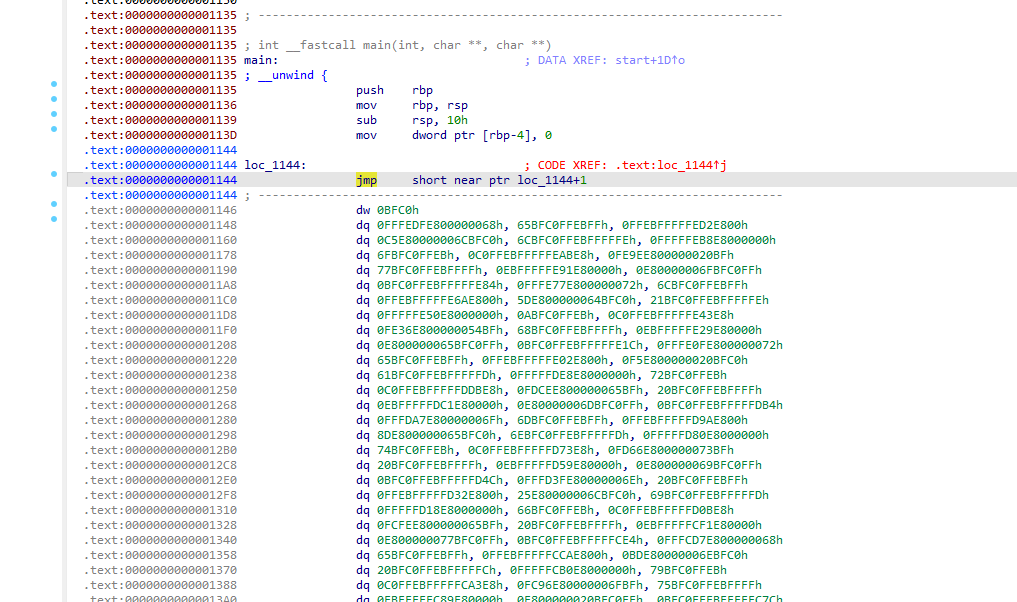
发现程序从
jmp short near ptr loc_1144+1
开始就无法分析,推测是jmp花指令导致IDA 认为既像代码又像数据,因此无法进行分析
花指令是怎么搞乱反汇编的?
搞乱“控制流”——让工具判断错“往哪儿走”
比如很经典的一种:
jmp short $-1 ; EB FF → 无限自跳,死循环
; 后面其实还有一大段正常代码
- CPU 真实执行:
跳到自己这条指令,又跳回来 → 死循环,后面的代码根本不会被执行。 - 反汇编器视角:
- 它沿着控制流往下分析,看到
jmp,就认为: “后面这条指令永远执行不到,是不可达的” - 于是 后面真正有用的代码,被当成“数据”或“垃圾”直接忽略;
- 函数边界、控制流图全乱。
- 它沿着控制流往下分析,看到
再加上各种“假跳转”“永远不会成立的条件分支”(所谓 opaque predicate,永真/永假的条件判断),就可以让 IDA 一会觉得往左走,一会觉得往右走,分析路线被拧成麻花。
搞乱“指令边界”——让工具把数据当代码、代码当数据
反汇编有两种常见策略:
- 线性扫(linear sweep):从某个起点一个字节一个字节往下解码;
- 递归下降(recursive descent):从入口跟着跳转走,只解自己认为“能到达”的地址。
花指令可以故意制造重叠指令或“伪代码”:
db 0x90, 0x90, 0x90, 0xE8, 0xAA, 0xBB, 0xCC, 0xDD
; 这一串既可以被解释成一堆 NOP + CALL
; 也可以被解释成完全不同的几条指令
- CPU 只按真实执行路径那一种解码;
- 但反汇编器如果从“错的边界”开始解,就会得到一堆看似莫名其妙的指令;
- 再加上一些奇怪的
jmp/call,就会导致 函数被切成多段,伪代码特别割裂。
搞乱“函数识别”——工具找不到 main / check_flag 的真身
像 IDA 识别函数的时候,会用一些套路:
- 看是否有典型的函数前言(
push rbp; mov rbp, rsp); - 看有没有被
call引用; - 看返回前是否有
leave; ret等模式。
花指令可以:
- 在函数中部插入奇怪的
ret/jmp/ “假 call”, - 让 IDA 以为“这里是函数结尾了 / 这里是新函数开始”,
最后结果:
- 一个本来很简单的
check_flag,被拆成 5~6 个小函数; - xref 图一片乱麻,伪代码怎么看都不成体系;
- 你就会感觉:“怎么没有地方在真正比较 flag?”
——其实比较逻辑是有的,只是被撕碎了。
遇到花指令逆向比赛里常见几招:
- 直接 patch 花指令
- 把
jmp $-1这种死循环改成nop nop; - 把永真/永假条件改成不跳转;
- 让控制流恢复正常,再让 IDA 重新分析。
- 把
- 把代码当数据,自己写脚本扫模式
像 wordy 那题,我们直接:- 不管这堆指令到底跑不跑;
- 反正我知道“每一段 FF C0 + 某字节就是一位字符”;
- 用 Python/IDAPython 按字节流扫描,还原字符串。
- 配合动态调试
- 用 gdb / x64dbg 让程序真实跑起来,看
RIP实际走哪些路径; - 发现某些
jmp从来不走,就可以认定那是花指令。
- 用 gdb / x64dbg 让程序真实跑起来,看
这道题最简单的方法是在 IDA 里用 Python 把“藏在指令里的字符串直接扫出来”的解法
start_adr = 0x1151
end_adr = 0x3100
for i in range(start_adr,end_adr):
if get_wide_byte(i) == 0xc0:
print(chr(get_wide_byte(i+2)),end='')含义:
get_wide_byte(i)是 IDAPython 的 API,用来读某个地址的一个字节。- 你从
0x1151一直扫到0x3100,逐字节检查。 - 每遇到一个字节值是
0xC0的地方,就认定: “这里是一个标记(锚点),真正有用的字符在后面偏移 2 个字节的位置” - 然后
get_wide_byte(i+2)读出那个字节,把它用chr()转成字符拼起来。
将上述代码用 IDAPython运行即可得到结果GFCTF{u_are2wordy}
Comments NOTHING